
はじめに
次の文章をまずは眺めてみてください。
“Chief Executive Tim Cook has jetted into China for talks with government officials as he seeks to clear up a pile of problems in the firm's biggest growth market. Cook is on his first trip to the country since taking over from late co-founder Steve Jobs"
文中で、ティム・クックを表す表現にはどのようなものがあったでしょうか?
文中の別々の表現が同じ実体を指しており、それらの関係を洗い出す要素技術は共参照解析(coreference resolution)と呼ばれ、検索や固有表現抽出との関連で重要なものになっています。
上記の文の中でティム・クックについて言及(mention)した部分にハイライトをつけたい場合は、以下のようなデータ構造がとれると良さそうです。
{Chief Executive Tim Cook: [Chief Executive Tim Cook, he, Cook, his]}
このようなニーズは人名・物体名の中でもさらに限られたカテゴリの実体をマーキングするという意味では固有表現抽出の意味を狭めた応用になっています。
本記事では共参照解析を行うためのライブラリとしてneuralcorefを触ってみて、その入出力の中身や意味について見ていきます。
neuralcorefについて
neuralcorefは分散表現に基づく共参照解析ライブラリです。*1
ライブラリの周囲には参照関係をビジュアライズするクライアント NeuralCoref-Viz もあり、このようなグラフを出力できます。
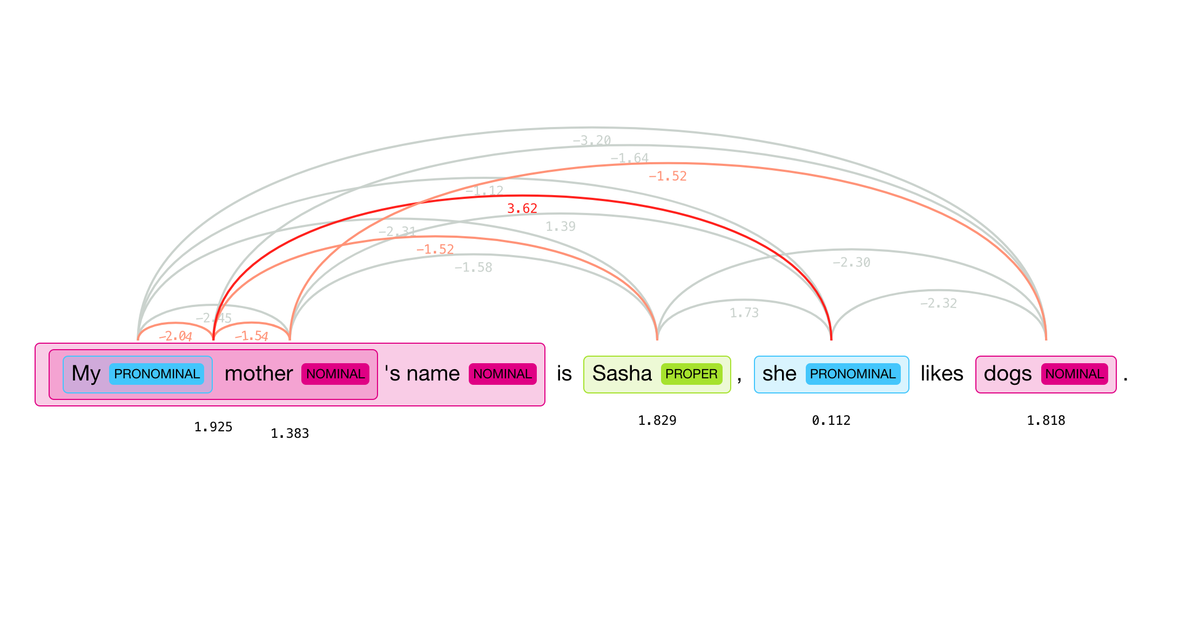
モデルは標準で英語のみの対応になっていますが、訓練することで他言語のモデルにも展開可能です
インストール方法
neuralcorefはspaCyプラットフォーム上で動くライブラリになっており、動作にはneuralcorefの他にspaCyのインストールも必要です。
筆者の環境 (python==3.8.10) 上では以下のコマンドでインストールし、ライブラリの動作を確認しています。
pip install spacy==2.1.0 pip install neuralcoref==4.0 --no-binary neuralcoref python3 -m spacy download en
動作確認
まずspacyのパイプラインに共参照解析を行うneuralcorefのプラグインを追加します。
In
import neuralcoref import spacy nlp = spacy.load(‘en’) neuralcoref.add_to_pipe(nlp) nlp.pipeline
Out
[('tagger', <spacy.pipeline.pipes.Tagger at 0x7f315b0d5e20>),
('parser', <spacy.pipeline.pipes.DependencyParser at 0x7f315b0bffa0>),
('ner', <spacy.pipeline.pipes.EntityRecognizer at 0x7f315b0e3520>),
('neuralcoref', <neuralcoref.neuralcoref.NeuralCoref at 0x7f315aec8970>)]
これだけで共参照解析を行う準備が整いました。
先程の文章をパイプラインに入力し、どのような出力を得るか確認してみます。
In
doc = nlp("Chief Executive Tim Cook has jetted into China for talks with government officials as he seeks to clear up a pile of problems in the firm's biggest growth market. Cook is on his first trip to the country since taking over from late co-founder Steve Jobs.")
doc._.coref_clusters
冒頭に紹介したような出力を得ます。
Out
[Chief Executive Tim Cook: [Chief Executive Tim Cook, he, Cook, his], China: [China, the country]]
この ._.coref_clusters でアクセスできるプロパティは共参照解析の結果を表したものです。
共参照解析では実体ごとに対応した文中の表現の関係をクラスタ(Cluster)と呼び、このプロパティでは共参照解析の結果としてのクラスタのリストにアクセスできます。
クラスタ経由で以下のattributeにもアクセスすることが可能で、共参照の実体と参照元のリストが取得可能です。
- main: 共参照の実体と思われるテキストのSpan
- mentions: 共参照の参照元となっているテキストのSpan
In
doc._.coref_clusters[0].main
Out
Chief Executive Tim Cook
In
doc._.coref_clusters[0].mentions
Out
[Chief Executive Tim Cook, he, Cook, his]
なお、._. はspacyのパイプライン特有のインターフェイスであるExtension attributeを利用するときに用いる表現で、nuralcorefでは ._. を通じて各種結果にアクセスできます。
解析時のオプションについて
neuralcoref.add_to_pipe(nlp, greedyness=0.75) のようにパラメータを指定することでクラスタの作られやすさを調整したり、頻度が少ない単語への個別対応を行えます。以下主なパラメーターです。
- greedyness: 0~1の値を指定して共参照のクラスタの作られやすさを調整できます(デフォルト0.5)
- max_dist: 共参照を生成する時にどれくらい手前の先行詞まで考慮するかを調整できます(デフォルト50)
- max_dist_match: 先行する実体へのメンションが名詞等だった時に、max_distを超えてどのくらい手前までさかのぼって参照を生成するかを調整できます(デフォルト500)
- blacklist: 共参照解析をI,meなどの代名詞を含めて行うかどうかを決められます(デフォルトTrue)
- conv_dict: 人名などの頻度の少ない単語の分散表現を頻度の多い単語の分散表現に置き換えて共参照解析します
共参照解析と照応解析との関係
共参照以外にも文中の言語表現が別の表現を参照する事象として「照応」という概念がありますが、これらは微妙に異なる概念です。共参照はテキスト中の表現から実体への参照を表すのに対し、照応は同格、代名詞などで表される照応詞が文中の表現を参照する方向にフォーカスします。この2つの概念の整理についてはコロナ社の照応解析について書かれた書籍が詳しいです。
文脈解析- 述語項構造・照応・談話構造の解析 - (自然言語処理シリーズ) | 笹野 遼平, 飯田 龍, 奥村 学 |本 | 通販 | Amazon
この記事を書いた人

yad
ビリヤニ食べたい
*1:Kevin Clark and Christopher D. Manning. 2016. Deep Reinforcement Learning for Mention-Ranking Coreference Models - ACL Anthology