
最近、身近なスモールデータをさくっと分析してみる機会があったので、過程をまとめてみました。スモールデータの解析であっても、前処理、可視化、示唆出しなどデータ分析に必要な所作というのは変わりません。ステップに分けながら紹介したいと思います。
今回はツールにGoogle Spreadsheetしか使っていないので、ノンエンジニアのビジネスサイドの人であっても同じ分析を回すことができます。Google Workspace(Gsuite)を使っている企業であれば紹介した生データも取得ができるかと思いますし、30分くらいしかかからないので、試してみると面白いかもしれません。
今回取扱いたいデータはGoogle Meetのログデータです。COVIDの影響で営業や採用文脈でリモートMTGが増えました。「最近、リモートMTGのちょっとした遅刻、多くない?」という社内のふとした問題提起から、実際にログをみることで「ちょっとした遅刻」がどれくらい発生しているかを可視化してみたいというモチベーションが生まれました
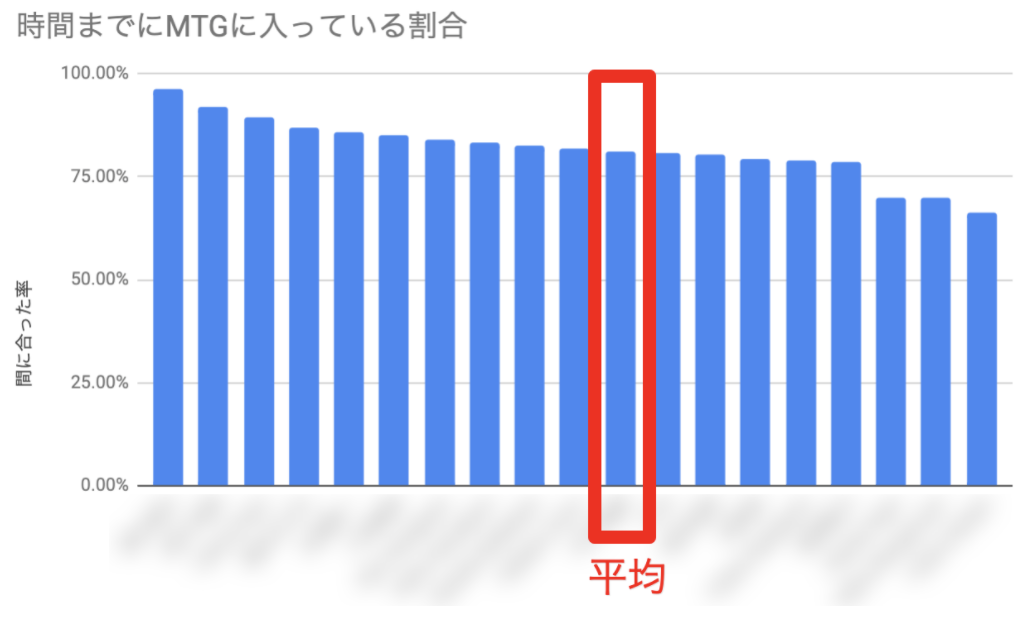
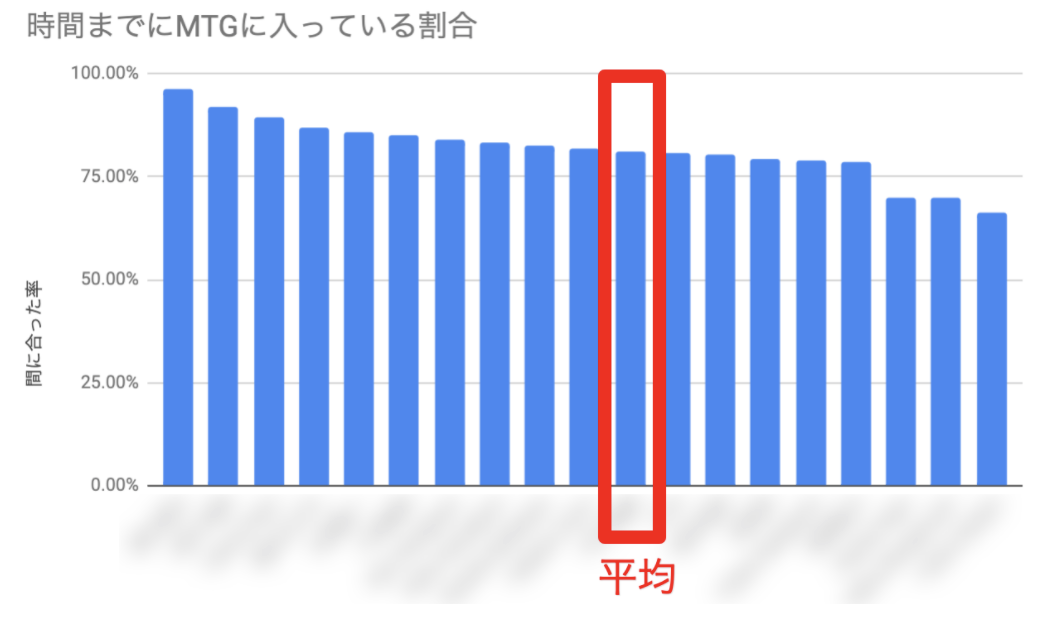
結論としてこんな感じの可視化を得ました
目次
- データの取得
- 生のデータを読む
- 前処理をする
- 可視化をする
- 味わう
データの取得
まずは生データの取得からです。今回はGoogle BusinessのAdminコンソールからMeetのLogデータを出力します。「Report」> 「Google Meet」 > 「ダウンロード」でダウンロードが可能です。Googleスプレッドシートかcsvか選べるようになっています。今回は30分クッキングということで、スプレッドシートで出力してみます。 データ分析のツールといえばJupyter notebookやRだと思います。が、個人的にはExcelやSpreadsheetも使い所によって、すごく強力なツールになると思います。特にスモールサイズのテーブルデータを色々いじくりまわす時にはこちらの方がスピードが出ることも多いのではないでしょうか。

生のデータを読む
出力されたファイルを開くと、下記のようなカラムがあることがわかります。(一部抜粋)
- 日付
- イベント名
- イベントの説明
- 会議コード
- 参加者 ID
- 組織外の参加者
- クライアントの種類
- 主催者のメールアドレス
- プロダクト タイプ
- 期間
- 通話の評価(5 段階)
- 参加者名
- (その他60項目程度)
今回の分析のモチベーション「みんな時間通りにMTG入ってる?」という論点から考えると、参加者IDと日付、期間などの情報が特に興味がある情報です。
参加者IDは欠損値も多いことにすぐ気づきます。他の項目と照らし合わせてみると、これは組織外の参加者とMTGをしている時にはこの項目が入ってこないということがわかります。

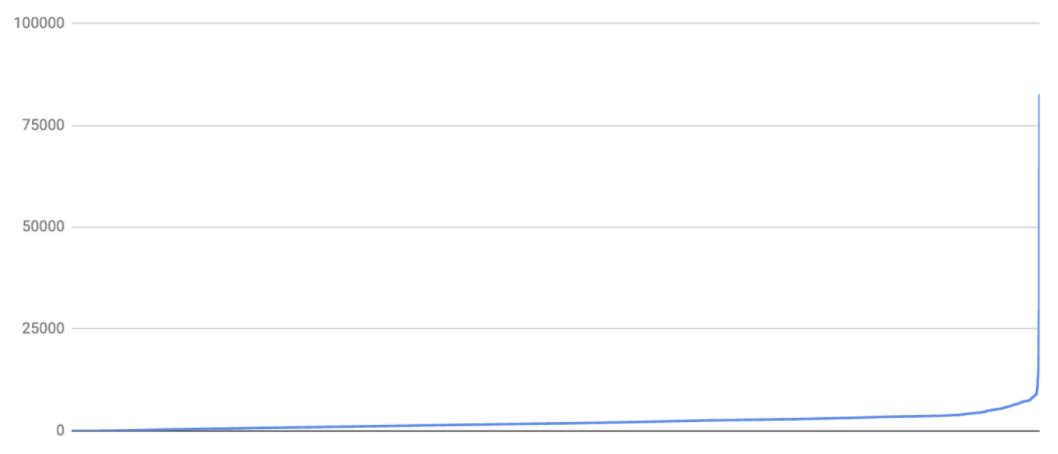
また、「期間」には整数値が入力されています。これが示す値がどういうものなのかよくわかりません。まずは雑に分布を見てみます。雑にみる時は全部の値をsortしてから、グラフで出してみるのを初手でやることが私は多いです。結果、3600くらいまでの値が多く、そこから少数のレコードでいきなり増加していき、最大値は82649だということがわかります。なんだか3600くらいまでとそれ以上で全然違うメカニズムの値がありそうだなという感覚を受けます。
もうちょっとよくみてみたかったので、ヒストグラムにしてみました。バケットサイズは自動にしつつ、上の方に異常値があったので、「異常値のパーセンタイル」に「5%」を設定します。こうすると、上と下の異常値は一つのバケットに入れてくれるので、ぱっと見わかりやすくなります。
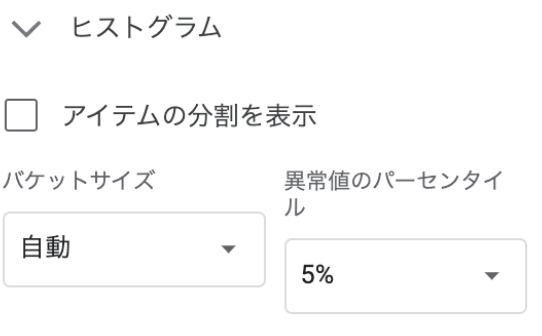
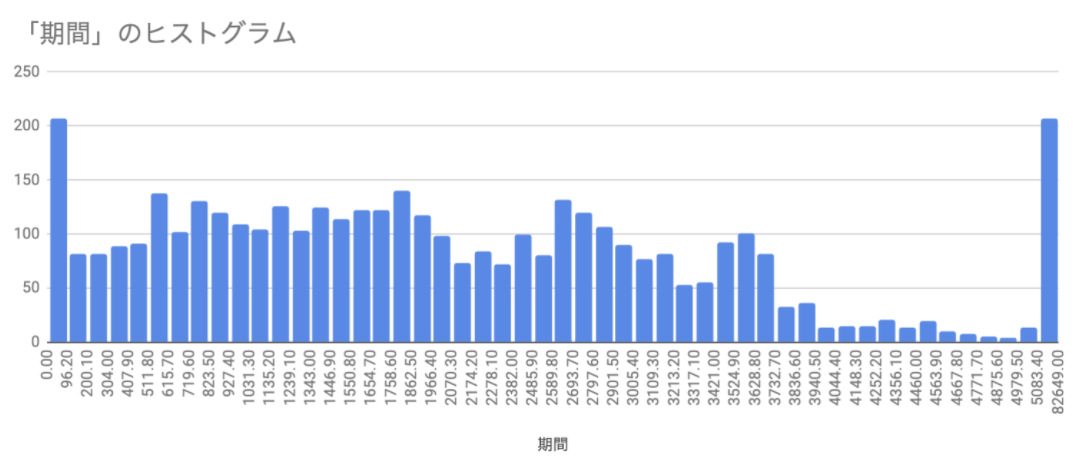
こんな感じになりました。これをみると「期間」は「接続時間の秒数」を指しているのではないか、ただし、一部の値はバグっているのではないか?ということに気がつきます。
- 異常値を除けば3600あたりから急に値が減っています。これはGoogle CalendarでMTGを入れるとき、ほとんどのMTGは1時間以内しか時間を取らないからだと思われます。
- 3600秒まで、を見てみると60分あたりの山、45分あたりの山、30分あたりの山、15分くらいまでの山がなんとなくあることがわかります。これは実際にカレンダーで設定しやすいMTGの時間帯と対応している可能性があると思います
- 90秒以内の異常値は接続不良などがあげられるかと思います。「マイクが調子悪そうだからスマホで入り直す」みたいな事象はこちらにあげられるかと思います。
- 5000秒以上のめちゃくちゃ長いレコードについては、実際にどういうレコードか眺めてみます。幸い、自分の入ったことがあるMTGもあったので、その時のカレンダーを辿ってみるものの、そんなに長く通話していたわけではありません。ここから上のカウントはもしかするとなんらかの計測バグなのかもしれません
- なんとなく「画面共有」を使っていた回が多いのかもしれない? という感触は持ちましたがあんまり確信はもてていないです。ここはふかぼっていません。
また「日付」のところにはタイムスタンプがおされていますが、一体開始時刻か終了時刻か、はたまた別のレコードなのかはぱっと見てよくわかりません。しかし、ここは自分のMTGの記憶でたぐると「会議を切断した時刻」であることがわかります。
前処理をする
「みんな時間通りにはいってるか知りたい」というモチベーションからすると「日付」のタイムスタンプから「期間」の秒数を引くことで「入室時刻」がわかるのではないか? とわかります。
Spreadsheetではこんな感じで計算をしました。
- 想定入室時刻 = <日時が書いてるセル> - TIME(0,0,<秒数のセル>)
- 想定入室時刻の「分」だけを取得 = MINUTE(<想定入室時刻のセル>)
無事に想定入室時刻が取得できたので、人をキーにしてピボットテーブルを作成し、集計してみます。この際に、上記のゴミデータが混ざらないように下記のフィルタをかけます。
- 参加者IDが登録されているレコードのみ(社内の人である)
- 7200秒未満のレコードである(上の外れ値を除去)
- 1200秒以上のレコードである(quick callなどを除去し、予定されたMTGに絞るため)
可視化をする
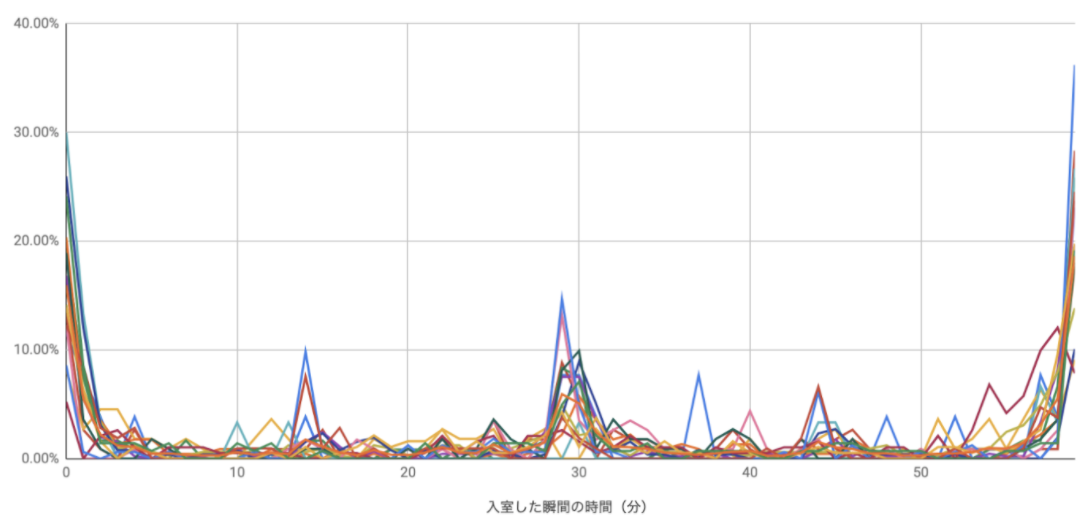
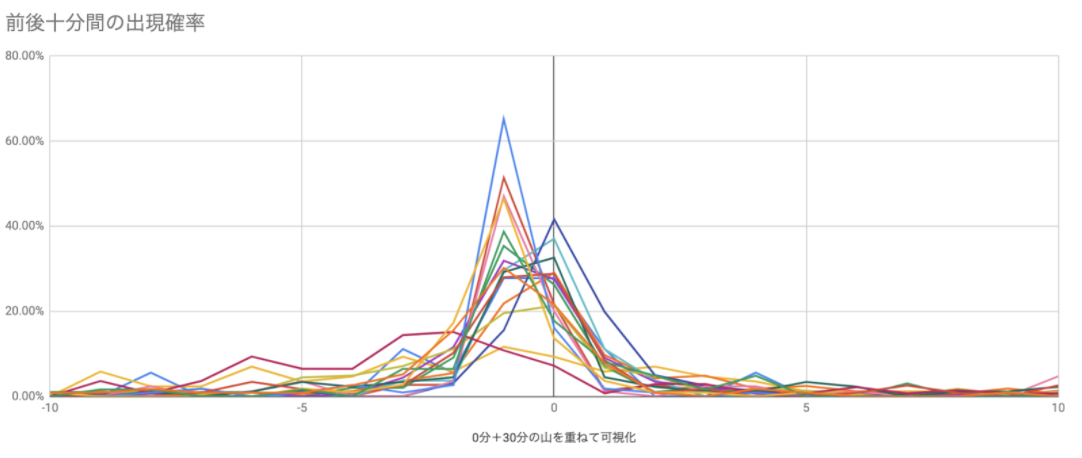
すると上記のような分布が得られます。一つ一つの色が一人のIDと対応しています。横軸が「分」で、縦軸が割合になっています。こうやってみると、一番大きな山が「0分」付近(グラフでいうと左端と右端)に分布していて、次に大きな山が「30分」付近にあることがわかります。これはほとんどのMTGが「X時00分」もしくは「X時30分」から予定されることを考えると非常に自然な分布に見えます。
では、上記のグラフの中で「X時00分」と「X時30分」の前後10分間のみを取得して重ね合わせてみると、「MTG前後の入室状況」がより可視化されるのではないか、とわかります。
やってみると。。。
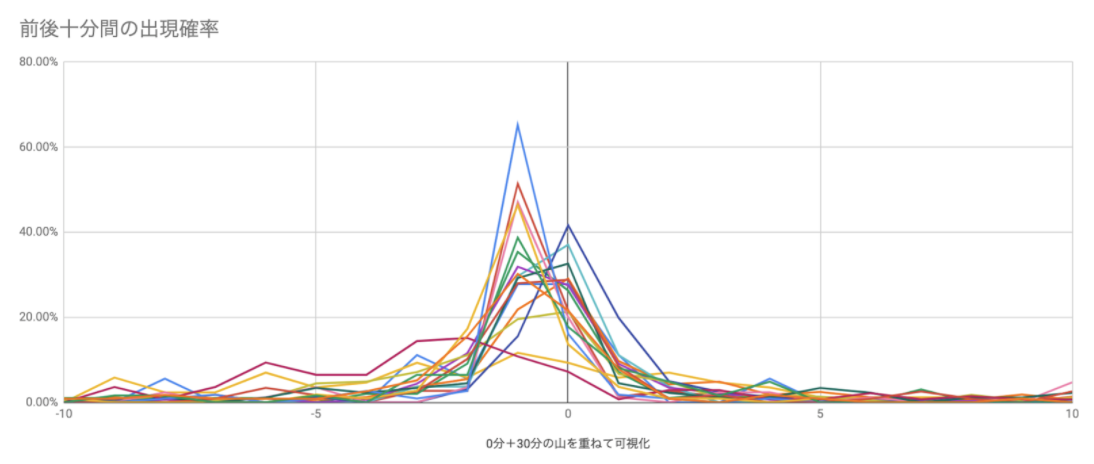
こんな感じになりました。綺麗に「MTGのちょっと前」に人がたくさん入ろうとしてきているのが見えますね。(中央がMTG開始時刻) ここから、「MTGの前後十分間の中で、開始時刻までに入室した率」を人ごとに計算してみます。すると、冒頭で出したような「人物ごとの『間に合った率』」が算出できます。また、それぞれの人が平均よりどれくらい間に合っているのか、どれくらい間に合っていないのかという程度も可視化がされます。
味わう
なんか結果っぽいものが出ましたが、一足跳びに結論に飛びつくのは危険です。データを味わった上で、本当に計算は正しいのか、言えることは何なのか、この分析の限界があるとするとどういうところか、ということを考える必要があります。回りのデータを扱う仕事をする人を見ていると、できる人であればあるほど「結果を正しく疑う」という所作がきちんとできているなと感じます。
データ分析は適当にやっても答えっぽい数値が算出できてしまいます。しかし、それをどこまでどう信頼すべきかの判断はまた別の話です。途中でとんでもない計算ミスをしていても気づかずするっと集計されていき、それをベースに意思決定が発生してしまう、というケースは最悪ですが、割と起きている事象かと思います。
比較的こぢんまりした今回の分析の中でも、実はデータ分析をする人が操作できるレバーというのは比較的多岐に渡ります。今回で言えば、例えば「期間」の異常値をどこまで弾くべきか、集計の際にどういうフィルタを噛ませるべきか、30分の山を足し合わせるべきか、などが挙げられるかと思います。これらのレバーを無意識のうちに分析者の仮説に有利な方に傾けていないかどうか。自分がフェアな分析をできているか、批判的に引いてみてみるというのはとても重要です。
今回の例で言うと、出た結果を見て定性的に不思議に思うところはないかどうか、体感と齟齬があるところはないか、この算出プロセスで結果が狂うとしたらどういうものがあるか、ということを考えていきます。
- 算出された傾向を何人かに聞いてみて、違和感があまりないことを確認
- 外れ値の人に聞いてみるのが有効
- 「0:0x」分からはじまるMTG等が定例で入っていたりすると不利になりそう
- アドホックにいきなりはじまったCallなのか、予定されていたMTGなのかの区別はレコード上できないので、アドホックなMTGを不規則にガンガンやっている人がいれば数値上不利になる可能性がある
- 回線や機器が不安定だったりして、繋ぎ直しを頻繁にしている人は計算上不利になりそう
- 上記のようなぶれは生じるので、正確ではないことには注意しつつ、大きな傾向は信頼できそうだとわかった
まとめ
身近にあるデータをがちゃがちゃといじるだけであっても色々発見や工夫のしどころはあるものです。小さいデータであっても大きいデータであっても、以下の大きな流れは共通しているかと思います。
- まずは一行一行をちゃんと読む
- 欠損値、外れ値に対して対処する
- データの分布をみることで性質を掴む
- ちょくちょく可視化して体感とずれがないか、どういう操作が有効か考える
- 出てきた結果にすぐ飛びつかない
- 「どういう限界があるか」、「どこまでの示唆を読み取ってよいか」、「本当に計算はあっているか」をいろんな角度から考えてみる