組織の情報爆発
突然ですが組織で働くすべての皆さん、所属組織のルールや方針、意思決定やその背後の理由についてどの程度把握されているでしょうか?突然理由も知らされず組織ルールや方針が更新されたり、日々の仕事において必要な承認や確認の取得に時間がかかっていないでしょうか。
MNTSQでは、
- (センシティブな個人情報を除いて)組織の職位やロールによらず誰もがアクセスできるようにする
- そのためにドキュメント駆動で意思決定や相談記録を残し、誰もが非同期でそれらにキャッチアップしながら賛否や新案を提案できる
- GitHubのIssue機能を介して、ゴミの分別ルールからビジョンレベルの意思決定まで誰もが発議できる
などの文化を大切にしています。これらの効用については様々な発信があるので、他の記事に譲りますが、同時に次のような悩ましいトレードオフ問題に直面しています。
- 組織の拡大に伴って発信される情報が非線形に増える(活発なことは大変良いが)
- それに伴っていまのタスクや会議に必要な情報のアクセシビリティが低下する(検索・優先付与の難度が上がる)
- 新しく入ってきた人ほど不明な概念が増え、キャッチアップ難度が上がっていく(SaaSという1枚岩プロダクトをみんなで連綿と作っているので、咀嚼しないといけない情報分量が大きいという弊社特性もある)
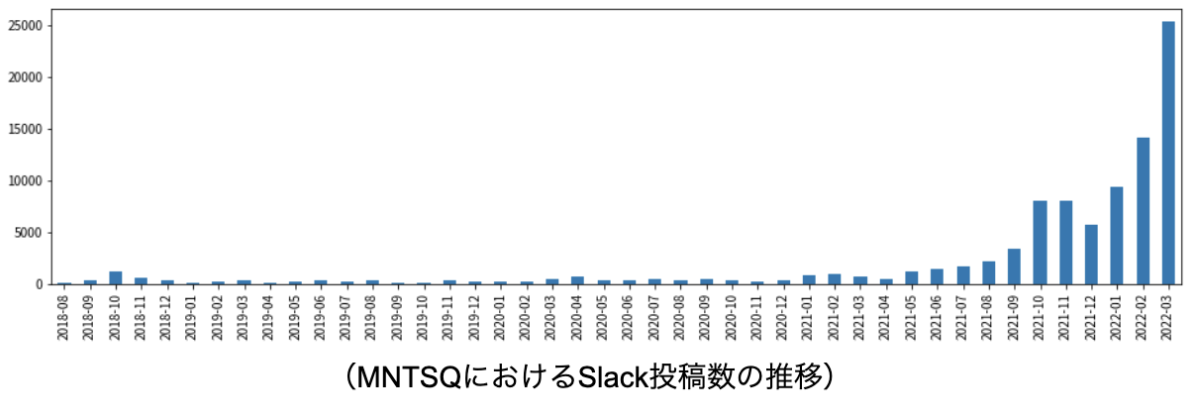
社内の発信メディアとしては、日々のslackやdocsやGitHubやらが枚挙できますが、入社して数ヶ月の私としては、アサインタスク遂行を丁寧に完遂することを主目標に据えつつも、GitHubに挙がっている組織Issueのキャッチアップが蝸牛の歩のごとく進まないことを課題に感じておりました。 というのも入社時点でMNTSQのGitHubレポジトリにはIssue総数が2kほども転がっており、技術的なものはそれぞれが非常に込み入って見えました。(ちなみにrailsレポジトリのイシュー数は執筆時点で0.3~0.4kぐらい。流石にvscodeは5k超えとかだけど...)
またGitHubのUI上、1本釣りやリストアップ型の体験は用意されているけども、サンプリングした上で全体の関係性や位置付け、優先順位を把握するのがどうも難しい印象を受けていました。 ネット上の共感者を探してみるとこんなのを見つけました。
Issues also show whenever they are mentioned by other issues or by commit messages. It is apparent that all these concepts and mechanisms are deeply interconnected. However, GitHub shows all this information in textual form and shows the interconnections through hyperlinks, which hinders a comprehensive understanding of the evolution of an issue.
この文言が完璧に私のもやもや感を明言化していました。GitHubではUI上イシューの想起関係などが見えにくく、問題解決において重用なサブタスクに分割することなんかにも心理障壁があったりします。特にテキスト情報処理に優れた人と、映像や概念で情報処理する傾向にある人だと前者寄りのUIに感じていました。
この問題に対して、試しにIssue間のリンク構造を可視化してみることにしました。 そうすることで全体における位置付けや分類が多少なりとも進むのではないかという気がしたのです。
GitHubイシューの関係性をグラフ構造で可視化する
Step1. GraphQLによるリソースの取得
ググってみると、同じアイデアを持った人がすぐに見つかりましたので、こちらを元に味付けしてみることにしました。 GitHub Issues Graph with Netlify and GraphQL
基本的なアイデアはIssueのメンション関係を取得し、グラフ化することです。同時に以下のような情報も含められるとよいと感じました。 誰の起案か=Ownerは誰か コメント 誰が参与しているかもフィルタしたかったので取得(例えば代表や社内のマネージャが関わっているイシューは優先度や解像度が高いかもしれないといったこと) ラベル(MNTSQでは各イシューに☆1~3でざっくりと優先順位をつけているため、これは最低限取得したい。)
以上、簡単な初期仮説を元に、一旦はopenなイシューに絞って社内Issueを管理しているレポジトリから必要な情報をGitHubのGraphQL APIを介して取得します。 最終的な取得スクリプト(TypeScript)は以下のような形で、この結果を一旦適当な場所に保存して、それをパースしていきます。
const { Octokit } = require("@octokit/rest") const fs = require('fs') // Create a personal access token at https://github.com/settings/tokens/new?scopes=repo const octokit = new Octokit({ auth: "Your access token here.", //ここでは簡単のためベタ書き }) const targetOwner = "hoge" const targetRepository = "huga" const fetchIssues = (endCursor: any): Promise<any> => new Promise((resolve) => { setTimeout(() => { let fetchRes = octokit.graphql( `{ repository(owner: ${targetOwner}, name: ${targetRepository}) { issues( first: 100, ${endCursor ? `after: "${endCursor}"` : ''}, states: OPEN) { totalCount pageInfo { startCursor hasNextPage endCursor } edges { node { number url title author { login avatarUrl } body labels(first: 10) { nodes { id name } } comments(first: 50) { edges { node { author { login avatarUrl } } } } timelineItems(first: 100, itemTypes: CROSS_REFERENCED_EVENT) { totalCount pageInfo { startCursor hasNextPage endCursor } nodes { ... on CrossReferencedEvent { source { ... on Issue { number } } } } } } } } } }` ) resolve(fetchRes) }, 500) }) const getAllIssues = async () => { let curCallNum = 0 let endCursor = '' const maxCallNum = 20 let edges = [] while (curCallNum < maxCallNum) { // eslint-disable-next-line no-await-in-loop let res = await fetchIssues(endCursor) // res = JSON.stringify(res) endCursor = res.repository.issues.pageInfo.endCursor let hasNext = res.repository.issues.pageInfo.hasNextPage edges.push(...res.repository.issues.edges) console.log(endCursor, hasNext) if (!hasNext) { console.log('All issues has been fetched.') break } curCallNum = curCallNum + 1 // console.log(`fetched res: ${edges}`) } return edges } getAllIssues() .then((res: any) => { let resJSON = JSON.stringify(res) fs.writeFileSync('./data/issueData.json', resJSON) })
Step2. 取得したJSONオブジェクトをd3.jsでグラフ構造化/可視化
次に上記スクリプトで取得したJSONデータを元に実際にグラフ構造を描画していきます。 またグラフ描画ライブラリとしてd3.jsを採用しました。今回はForceGraphを応用します。これを使うとこんな感じでグラフのnodeとedgeにいい感じに引斥力を与え、それを物理的にシミュレーションすることでいい感じに適当に集まったり離れたりしながら各nodeの位置を決めてくれます。
ここではコードの詳細は省略しますが、初期仕様としては上記情報爆発課題にかんがみて、以下のような機能を実装しました。
- ノードが個別のIssue、エッジが参照関係となるグラフの描画
- ただし孤立したIssueまで書き込むと情報爆発そのものを眺める羽目になるため、各ノードの次数(Incoming Edges+Outgoing Edges)に応じて描画するノードをフィルタできるようにする
- ノードの半径は上記の次数に応じて大きくする(ハブとなるイシューが一瞥できるようにする)
- 3段階の優先度ラベルに応じて金銀銅の外円を描画
- ノードの中にownerアイコンを描画する
- ノードをクリックすると詳細を右ペインで把握できるようにする(ここはGitHubの検索時UIを模す)
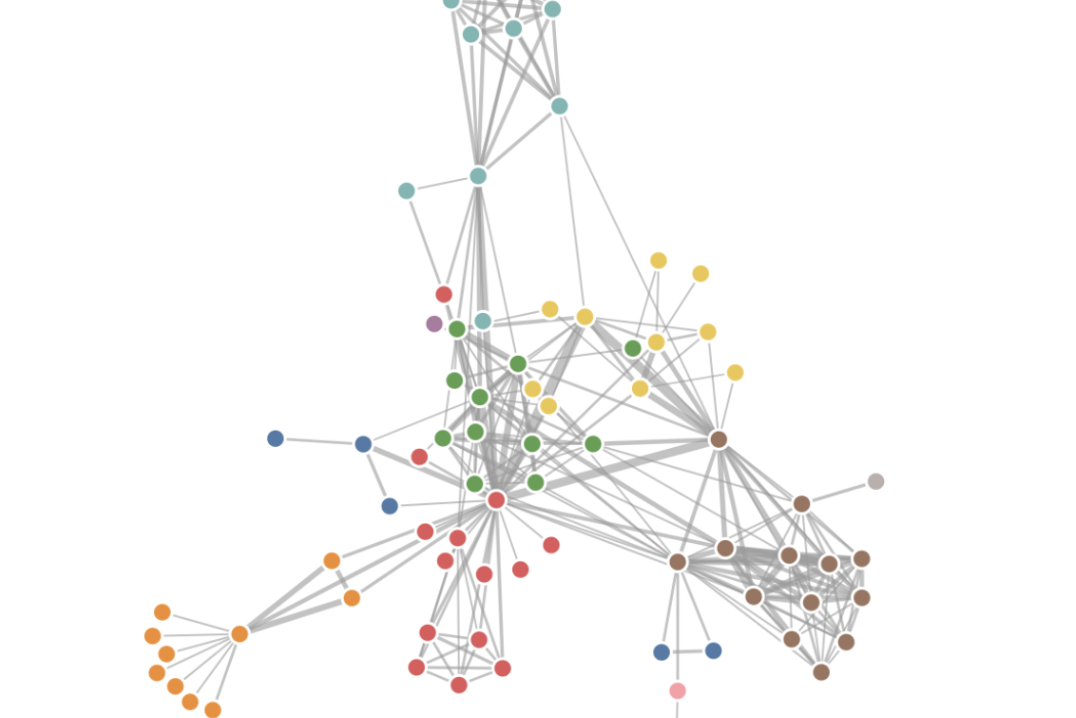
 俯瞰図
俯瞰図
さて、この可視化の結果どのような示唆や効果があったでしょうか。以下ドッグフーディングの結果をレポートします。
Issueグラフ作成の結果と示唆
このアプリケーションの使用感として、以下のような発見がありました。気づいた順に列挙してみます
- イシューをポチポチしていったときに、すべての情報がロード済みなのでダウンタイムなく内容確認できるスピード感はよい(俯瞰できる感は本家よりスムーズ)
- 上図でいうと、金/銀/銅色の円で一覧描画されるのでざっくり優先度をつかめる
- これはCOOを始めとして弊社各員の地道なイシュー回覧のおかげ
- GitHubでもラベルによるフィルタできるので比較した差分は小さいけど、金塊や銀塊あたりを発見するにはよい感じ
- 母艦イシューや関連性を中心に会社のメインイシューを把握できる
- 例として右下のクラスタ(金銀銅の混合山)はビジネスメンバが多く、関連するイシューは主に導入効率化に係るものが多い
- 弊社ではありがたいことに引き合い多く、一方で大企業法務のお客様は既に複雑かつ巨大な業務システムを抱えてらっしゃるケースが多く、このような事情で導入や整理が大変であるという関連課題がまとまっている
- 例として右下のクラスタ(金銀銅の混合山)はビジネスメンバが多く、関連するイシューは主に導入効率化に係るものが多い
- 左下の銀山は社内事務の効率化にかかるもので、個人的に肌感もてている感じではないものの、複数の当事者の間で問題意識が共有されているあたりからして無視できないのだろう
- 人の切り口で見る
といった具合にグラフ構造はメンバー間の想起の歴史を反映している点は意義深く、俯瞰性と偶発的発見に特化した可視化手段として一定有用だなと感じました。
改善案や課題
以上、良い体験や発見をベースに列挙していきましたが、改善点も同時に多くみつかりました。こちら列挙すると
- イシュー間のmentionが不十分
- むしろ孤立したイシューのほうが多く、それらの中に重用イシューが散在している場合もある
- 検索によるフィルタリングが同時にできるとよい
- duplicatedなイシュー、似たイシューをツール内で見つけられるようにできるとUXとしてかなり改善しそう(ただしそれによるGitHubとの差分は少ない)
- 既にイシューの概念構築がすすんでいれば、欲しい情報の一本釣りはGitHubで十分とも感じる
また情報爆発の対処法は誰かが整理したもの(或いはこのように自動的に整理されたもの)を受動的に享受するだけだと片手落ちだと感じました。
イシューからはじめよに記載ある通り、人間の「理解した」の本質は、概念間の関係を見出したり、逆に無相関であることが明らかになることによって訓練される想起ネットワークだと考えています。情報記述する側の各員による配慮やこういった自動的可視化の支援は最低限度必要であるものの、それらにかまけず自分からゼロベースで概念を整理する、配線するといった方向性を助ける方が、寧ろ本質的解決につながるかもしれないとも思い至りました。
とはいえグラフ構造はチャットツールのような1次元リスト構造や一通り関連情報がまとまっているクラスタ(docsに近い)、wikiやマインドマップのようなツリーに比べるとリソースフルかつ整理コストが低く(想起したらリンクすればよい!)、また上記の通り人間の概念把握トポロジーに近いと思われるため、整理と抽出のバランスがよい点が改めて良いなと感じました。
参考: 階層整理型WiKiはスケールしないー私は階層型整理は書き手側の読み手への配慮手段の一つだという考えですが(そのため書き手側に回るとつらさが出てくる)、ネットワーク型の情報整理の利点についてはscrapboxの考えが非常によくまとまっています。
