はじめに
こんにちは、MNTSQ株式会社でSREをやっている西室と申します。私生活ではゲーム以外でPCを使わないので、最新技術へのアンテナ感度はエンジニアとしては最低クラスです。未だにタッチタイピングができません。
さて、最近巷では「生成AIがすごい」だの「使えないと時代に取り残される」だの、何かと話題が尽きないですが、まだ業務にうまく活用できていないという方も多いのではないでしょうか? かくいう私も「なんか調べるのが億劫だな〜」と、ChatGPT以外には手を出していなかったのですが、半年ほど前に開発チームにDevinが導入されたので試しに使ってみたところ、これがなんともう世界が一変するくらい便利でした......。この感動を共有するために、本記事にて活用事例を紹介してみようと思います。
繰り返しますが、私はAIに関する専門知識もありませんし、技術が好きというわけでもありません。生成AIを便利に活用するだけなら高度な知識は必要ありません。
その前にDevinとは
いったいなんなんでしょう。私にはよくわかりません。半年前に会社の人が導入してくれました。詳しいことはChatGPTとかに聞いてください。他にもClaude Codeとかも流行ってるという噂を聞きました。
私にわかることは以下のみです。
- なんかお願いするとリポジトリのコードとかをみていい感じにPRを作ってくれる
- PRコメントやプロンプトを使って対話形式で追加修正もしてくれる
- 「ナレッジ」と呼ばれる約束事みたいなのを人間の言葉で設定できて、基本的にそれを守って作業してくれる
活用事例紹介
記事の趣旨から外れるため、生成したソースコードなどは載せていません。「こんな風に使えるんだ〜」というのを感じ取っていただければ幸いです。
仕組みを作らせる系
GuardDutyのアラートをGitHubにIssueとして起票するLambdaを実装してもらった
弊社SREチームではセキュリティ関連のさらなる充実をミッションにしており、GuardDutyを使用した脅威検出などの整備を進めています。今までの対応フローは
脅威検出 -> Slack通知 -> Issueの手動起票 -> 対応 -> Issueクローズ
という流れでしたが、Issueを手動で起票するのがいい加減大変になってきたため、この部分をDevinに自動化してもらいました。
※ 書いたプロンプト
<terraformファイルへのリンク>で定義されているaws_sns_topic.chatbot_guarddutyは、GuardDutyで脅威が検出された際、EventBridge -> SNS -> Chatbot -> Slackと通知を行うためのSNSである。このSNSからLambdaにもファンアウトして、以下のような処理を行いたい
1. 脅威のタイトルと同名のIssueをGitHubのmntsq-infraリポジトリに作成する
2. 本文には適当な概要と、検出結果へのリンクを貼る
3. guardduty/<レベル>のタグをつける<レベル>は脅威の重要度(低~クリティカル)
4. MNTSQ/sreのチームをアサインする
かなり大雑把な指示ですが、Devinはリポジトリのソースコードを読んで、どうのように実装すれば良いか、周りのコードとシンメトリーを合わせながら実装を行ってくれました。いきなり完璧なものが出来上がるわけではないので、PRにコメントする形で何度かやり取りをしました。同僚とチャットするような感覚で、ラフに不足箇所を指摘します。
※ やり取りの雰囲気(実際にはもうちょいコンテキストの深いやり取りもしています)
Devin 「できたよ。GitHub tokenが必要だからこうやって設定してね」
わたし「了解。Lambdaのソースファイルはそっちじゃなくてこっちに置いて」
Devin 「OK」
わたし「token平文でLambdaの環境変数に突っ込んでるのまずいから、処理の中でSSMから取得するようにして」
Devin 「ごめん、直したよ」
わたし「Lambdaに〜の権限つけ忘れてるよ」
Devin 「ごめん、直したよ」
わたし「動いたわ、サンキュー」
結果、GuardDutyで脅威検出した際には以下のようなIssueが起票されるようになりました!下手に人間が作業するよりも、綺麗なフォーマットで起票してくれる実装になっていて嬉しいですね。細かいトラブルシュートまで含め、PR完成までの作業時間としては4時間くらいでしたが、Devinがコードを書いている間の待ち時間をチャットの返信や細かいタスクに当てられるので、非常に効率的に作業ができました。
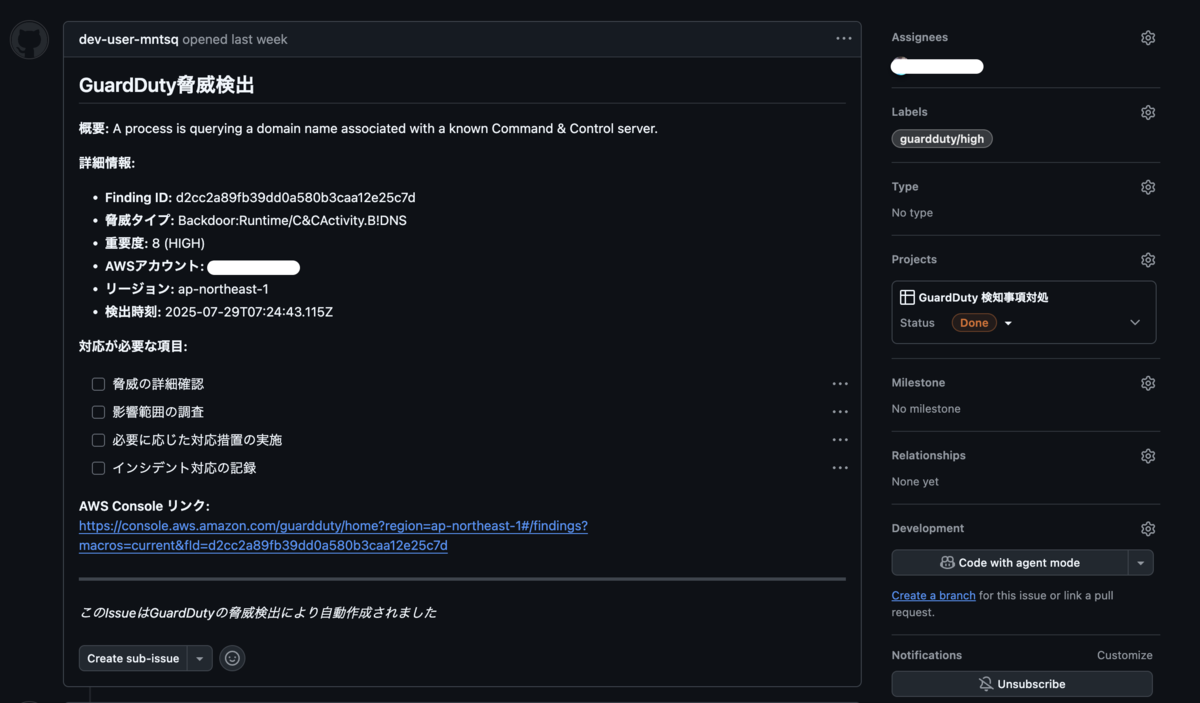
ECSタスク定義の差分をPRにコメントするGitHub Actionsの実装してもらった
弊社ではタスク定義のテンプレートをアプリケーションのコードと同じリポジトリで管理しています。アプリケーションに変更が入ると、CDによって自動でAWS環境のECSサービスの更新までが行われます。先日、タスク定義テンプレートの修正に不備があり、今まで値が入っていた環境変数が空になってしまったことによる障害が発生しました。障害を受けての恒久対策として、PR作成時に、CDによってタスク定義が変わる場合はその差分をPRにコメントするGitHubActionを作成してもらいます。
以下のようにプロンプトを書いてみました。
<リポジトリ名>に以下のようなGithubActionのワークフローを作成したい。
* <ブランチ名>へのPR作成をトリガに動く
* マージ後、デプロイのWF(deploy_clm, deploy_connectmail, deploy_ibreoffice, deploy_search_api)が動いた際に新規作成されるタスク定義の差分表示とバリデーションを行う
* deploy_clm, deploy_connectmail, deploy_ibreoffice, deploy_search_apiにて作成されるタスク定義のJSONと、ECSの最新のタスク定義JSONのenvironment以下の要素を比較し、差分をどのタスク定義の差分なのかがわかる形でPRにコメントする
* 新たに作成されるタスク定義のenvironmentにValueが空のものがあれば失敗させる
deploy_clmとかいっているのは、サブサービス毎のデプロイのWFのことです。弊社ではサブサービス毎にデプロイの単位を分割しているので、WFファイルも複数に分かれていますが、それぞれのWFの実装方法に結構な差分がありました。コードベースがごちゃついていることに加え、この丸投げするような指示の仕方がDevinを混乱させてしまい、見当違いのPRばかりが作成されてしまいました。
そこで、以下のように作業を分割しました。
- 似たような処理を共通化して実装差分をなくす
デプロイWF内のタスク定義JSONを生成するステップ群をcomposite化して、各デプロイのWFからはこのcompositeを使用してタスク定義JSONを生成するようにしてもらう - タスク定義の差分比較ロジックを共通化して再利用可能にする
inputに与えた、タスク定義JSONおよびタスクファミリーのlatestの定義を比較して、環境変数の差分を指定したPRにコメントするcompositeを作成する - バリデーションWFの外枠を整える
PR作成をトリガとし、コード差分があったサブサービスについてタスク定義を作成し、2で作成したcompositeを使用してタスク定義の比較を行うWFを作成する
1の作業でコードのシンメトリーが揃い、Devinがコード構造を理解しやすくなります。加えて2,3の作業のように変更が大きくなりすぎないように指示を出すことによって、Devinもやるべきことを間違えずらいし、レビューもしやすくなりました。Devinに指示を出すときは、新卒の社員にタスクを渡す感覚で分割すること、そもそも理解しやすいようにコードベースを整理しておくことが大切みたいです。
PR作成時に、タスク定義の差分が表示されるようになりました!

コード整頓系
デプロイWFの実装シンメトリを揃えてもらった
コードが整頓されていることが、Devinの活用のしやすさにつながることは前述のとおりです。であれば、コードの整頓もDevinにやってもらいましょう。
リポジトリに似たような処理が複数あるが、実装方法が微妙に異なる場合を考えてみます。まずは1つ自前で(Devinにやらせてもいいですが)お手本の修正PRを作ります。そしてDevinに以下のように指示します。
※先ほども例に挙げた、サブサービス毎のデプロイWFのシンメトリーを揃えてもらうための指示
<マージ済みのお手本PRのリンク>と同じように、.github/workflows/deploy_connectmail.ymも修正してください。以下の点に気をつけてください。
* 変数設定のロジックをset-variablesというjobに集約すること
* 変数ファイルの読み込みには.github/actions/load-env-variables/action.ymlを使用すること
注意して欲しい箇所だけプロンプトに書いておけば、あとはお手本を参照して綺麗に一発で作業してくれました。これをサブサービス毎に行い、デプロイWFの実装のシンメトリーを完全に揃えることができました。お手本があり、それを模倣して実装するという作業ではかなりの威力を発揮してくれるようです。
ハードコードされていたオートスケールのパラメータを変数化してもらった
terraformのvariableにすべき箇所をハードコードしてしまっているので、直してほしいというケースです。特に今回治したかった箇所は、カスタムメトリクス化している自前のキューのメッセージ滞留数を閾値としてオートスケールさせている箇所で、設定が複数のリソースにわたっています。人力で影響範囲を網羅するのが少し大変です。そんな作業も、リポジトリ構造を把握しながら作業してくれるDevinにお願いすれば一発です。
<関連ディレクトリ>以下にハードコードされているオートスケールの設定を、<変数ファイル>に変数として抜き出して、気軽に書き換えられるようにしたい。設定したい項目はここら辺。
* オートスケールの上限
* スケールアウトを行うキュー滞留の閾値
* 1回のスケールアウトでタスクを何台追加するか
* 1回スケールアウトしてから再度スケールアウトするまでのクールダウン時間
とりあえず実装方針を確認したいから、<サブサービス>についてのみ上記の対応を行なって
変更が大きくなる場合は局所に絞って変更するように指示を出すと、レビューがしやすいです。方針をレビューしたら、他の部分も同じように変更するように指示を出しましょう。この変更も、特に直しの必要はなく一発でやってくれました。こういう単純な作業は人間よりも明らかにAIの方が得意ですね。
壁打ち系
使い慣れていないリポジトリに大きな変更を行う際の調査・設計を手伝ってもらった
弊社ではインフラとアプリケーションのリポジトリは分かれており、私はアプリケーションのリポジトリには明るくありません。ところが少々アプリケーションリポジトリを読み込まないければならない事情があり、Devinに相談に乗ってもらいました。
※ ElasticSearchのインデクシングをBlue/Greenで行いたいんだけど......という相談
<リポジトリ名>について。<ファイル名>の"initialize"のタスクについて、その処理時間がプロダクト運用上大きな問題になっている。弊社では頻繁にインデックス構造の見直しがあり、その度にこのタスクを実行するが、その間インデックスが使用できなくなるため、サービスを停止してインデクシングを行なっている。
サービス停止を行わずにインデックスを更新できるように、blue/greenでinitializeのタスクを実行できるようにしたい。以下は現時点で考えているアイデアの箇条書き
* ノードではなくインデックスレベルでblue/greenの面を作る
* initializeタスク実行時、現在使用していない面について更新を実行し、使用している面はその間も停止時間なく使用可能とする
* タスク実行中にインデックスの追加・更新などのメッセージがキューに詰まれる時、それはblueとgreen両方の面の分積む(blue/green差分が生じないように)
* 更新が終わったら面の切り替えを行う
* 平時は使用していない面は落としておく
とてもざっくりしていて申し訳ないけど、
* もっと良いアイデアはないか
* このアイデアに追加したい項目はないか
* クラスレベルの抽象度で、実装するとしたらどのような変更を加えるか
など、考えを聞かせてほしい。
膨大なソースコードを読み込まなければ検討すらできないような大きな課題ですが、なんとものの数分で複数のわかりやすい図とともに実装計画をドラフトしてくれました!もちろん考慮漏れは多々あるので、少しでも疑問を感じたら実際のコードを読みにいって、方針の妥当性を確認し、必要なら直してもらいます。以下のようなやり取りを延々と続けて、気になる点をひたすら潰していきました。

2日ほどかけ、最終的に、とりあえず検証のために仮実装できるイメージを持つところまで到達できました。クラス図や処理フロー毎のシーケンス図も、プロンプトでのやり取りを反映しながらブラッシュアップしてくれました。作成してもらった図は、現在の構造を表すものまで含めると合計で10個になりますが、これを手で作ったとするとかなりの工数がかかったはずです。もちろん実際に実装を始めてみると問題も出てくるかもしれませんが、たった2日程度でほとんど手を加えたことのないリポジトリの(必要な箇所の)構造把握と、大規模な変更プランをイメージできるようになれるのであれば、破格の作業効率ではないでしょうか。
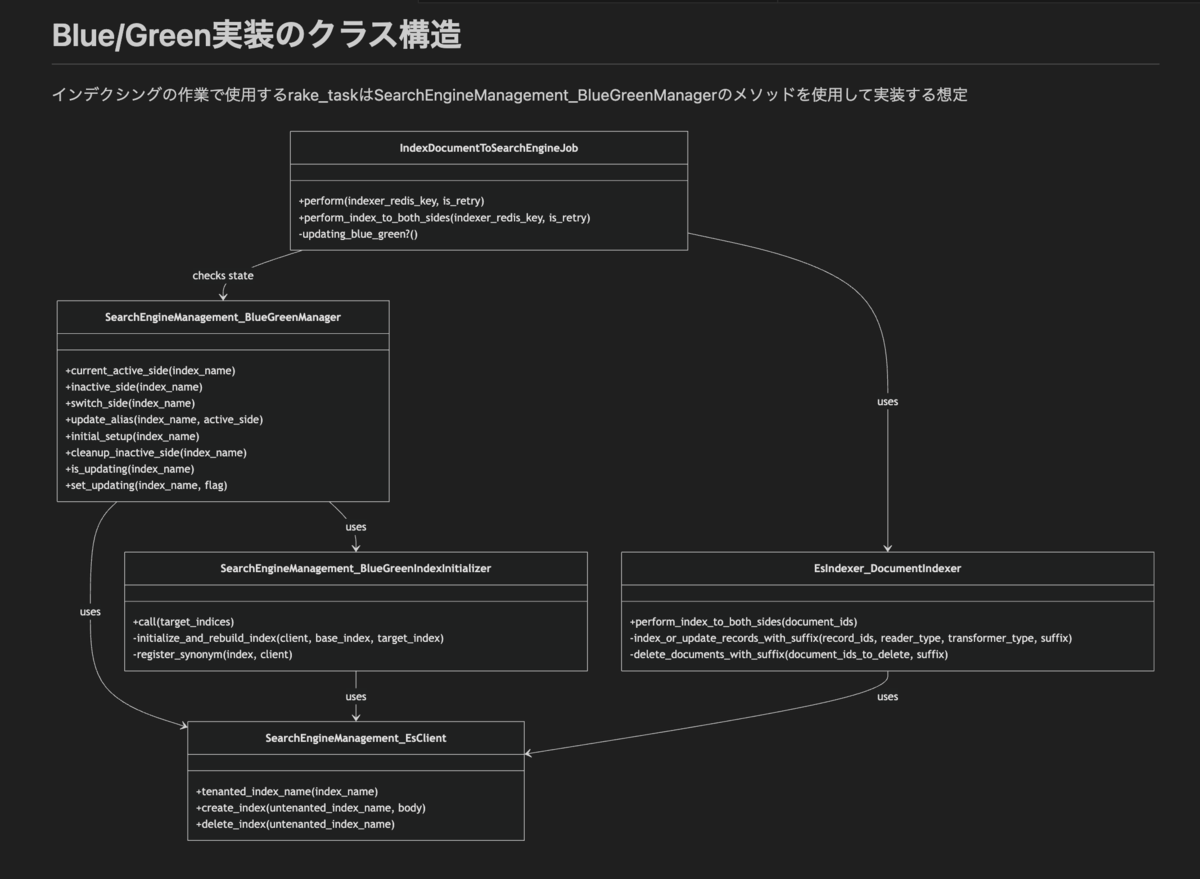
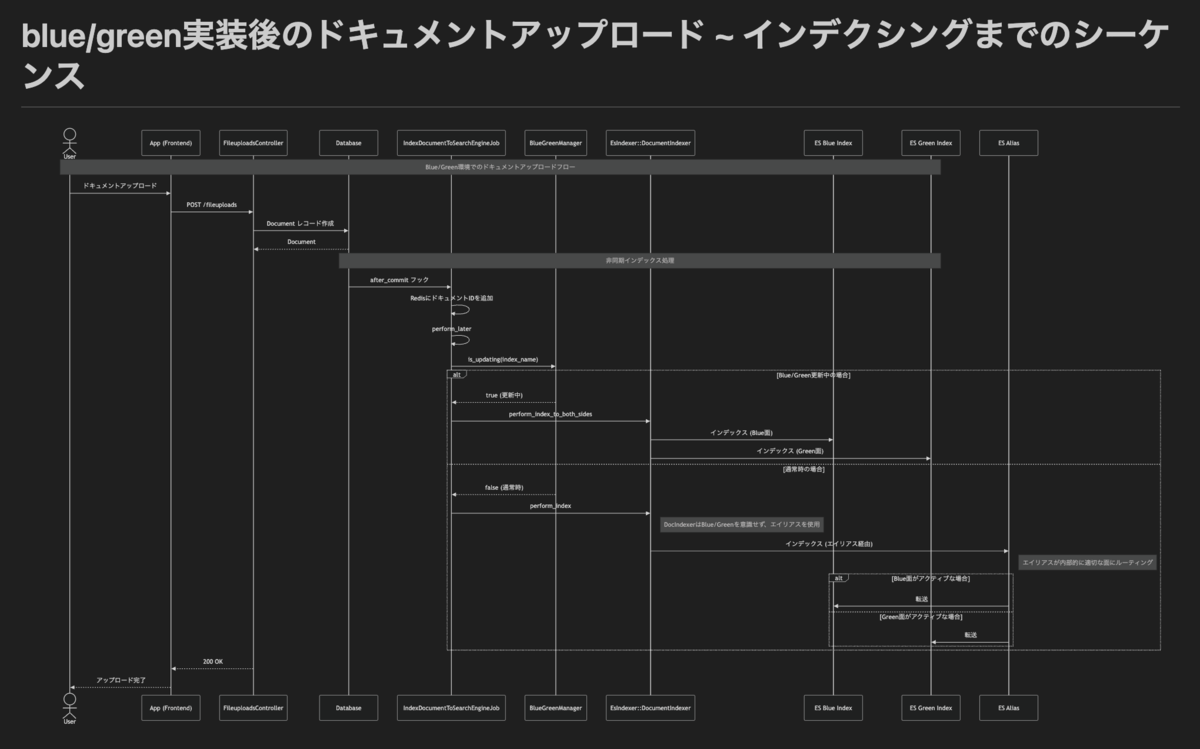
まとめ
Devinを活用するには
ダラダラと活用事例を書いてきましたが、結局のところ以下のようにまとめられると思います。
Devinを活用するための前提
- 適切なタスク分解・わかりやすい指示ができる
- コードベースがある程度整っている
- レビュー・動作確認を怠けないマインドを持っている(とても重要)
Devinは決して万能の存在ではなく、素晴らしく作業が早い新入社員と思って接するのがちょうど良いなと思いました。うまく指示を出してあげないと見当違いのことをしますし、ぐちゃぐちゃのコードを理解するのには人並みに手こずるようです。また、ちゃんと指示を出したつもりでも細かいミスはします。
Devinを使うべきでないシチュエーション
- タスクを言語化ができない場合
- 実装後の差分が大きくなり過ぎてしまう場合
これはシンプルに「自分が理解していないタスクは任せるな」ということです。言語化できないのは論外ですし、実装後の差分が大きくなりすぎるということは、そのタスクをきちんとサブタスクに分けられていないということです。(≒作業見通しが甘い)逆に自分が理解していて、適切な粒度に分けられるタスクは、積極的に任せて問題ないなと思います。しかし、理解できていないタスクを理解するための壁打ち相手としては優秀です。
おわりに
ここ最近クローズしたIssueを振り返ると、8割近くをDevinに実装をしてもらっていました。もう私いらないんじゃないかな?
というのは冗談で、生成AIはあくまでツールです。使う側がリテラシーを持って扱う必要があります。Devinを業務に導入するようになってから、決して大袈裟ではなく業務効率は倍以上になったと感じます。今後は、自分でコードを書けるだけでなく、生成AIに適切な指示を出し、その結果を正しく評価できることが、エンジニアの市場価値につながっていくのだと思います。
先ほど「Devinは新入社員と思って接するのがちょうど良いと」いう例えをしました。いかに彼らに的確な指示を出し、円滑に協力できるか。生成AIを扱う上で求められる能力は、いわゆる「コミュニケーション能力」に近いのかもしれません。(詳しい人はもっとプロンプトに関わるハックなど持っているのかもしれません。あくまで私くらいの活用レベルでの話です)この感覚が正しいのであれば、"そこそこ" 程度の技術力は、もはや大した強みにはならなくなってしまうのでしょう。磨こう、コミュ力。
MNTSQ株式会社 SRE 西室